[Pytorch] Learning Rate Scheduler 정리
머신러닝을 학습시키기 전 하이퍼파라미터를 설정할 때 epoch이 흘러가면서 적합하게 맞춰가면 안될까? 하는 생각이 있었는데 이미 있는 방법이었고 Pytorch 에서 제공하는 Learnig rate를 학습과정에서 조정하는 Learnig Rate Scheduler 라고 부르는 모듈이 있었다.
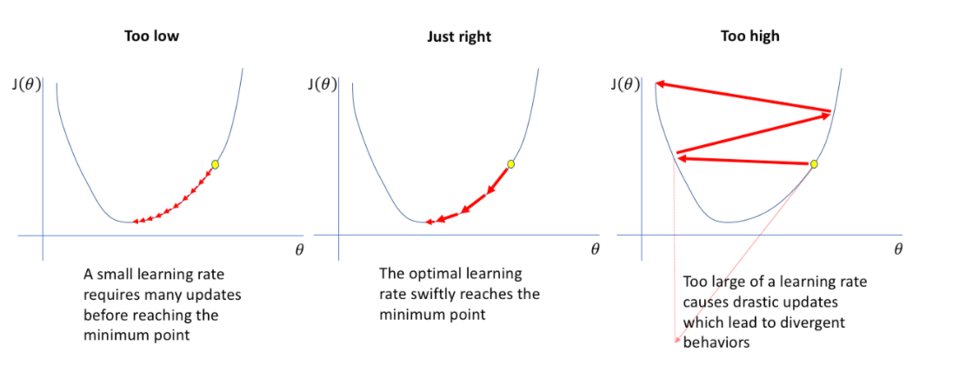
Learning rate 는 최적의 weight를 찾아나가는 보폭으로 너무 작은 값은 local minimum point에 까지 밖에 도달하지 못해 최적의 weight를 못 찾게 되고, 너무 큰 lr은 noise가 커져 weight를 못 찾게 된다.
그래서 Learning rate scheduler는 최적의 lr을 찾기 위해 최적의 값에 가까워 질수록 lr을 줄여 최적의 lr로 weight를 찾는다.
Learning Rate Scheduler
import numpy as np
import pandas as pd
import os
import torch
import matplotlib.pyplot as plt
for dirname, _, filenames in os.walk('/data/lr'):
for filename in filenames:
print(os.path.join(dirname, filename))사용하는 모듈
lrs = []
for i in range(10):
optimizer.step()
lrs.append(optimizer.param_groups[0]["lr"])
scheduler.step()
plt.plot(range(10),lrs)lr을 출력하는 코드
1. Lambda LR
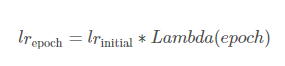
Lamda 표현식으로 Lr을 정한다. lr_initial 에 람다함수를 곱해서 learning rate를 적용한다.
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
lambda1 = lambda epoch: 0.65 ** epoch
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1)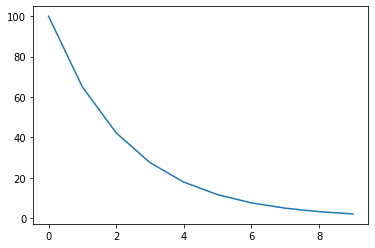
2. MultiplicativeLR

마찬가지로 Lamda 표현식으로 Lr을 정하는데 누적곱으로 lr을 정한다.
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
lmbda = lambda epoch: 0.65 ** epoch
scheduler = torch.optim.lr_scheduler.MultiplicativeLR(optimizer, lr_lambda=lmbda)
lrs = []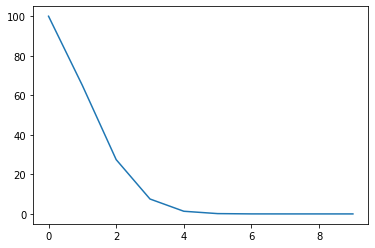
3. StepLR
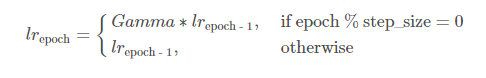
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=2, gamma=0.1)
lrs = []step size 마다 gamma 비율로 lr을 감소시킨다.
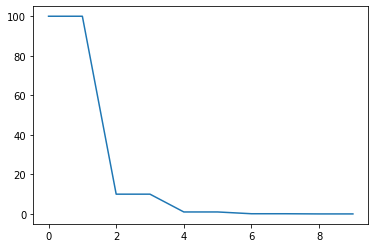
4. MultistepLR

model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=[6,8,9], gamma=0.1)
lrs = []
chatGPT가 말하는 MultiStep LR 과 Step LR 의 차이이다. 무슨 말인지 모르겠다.

좀 더 나은 설명인 것 같다.
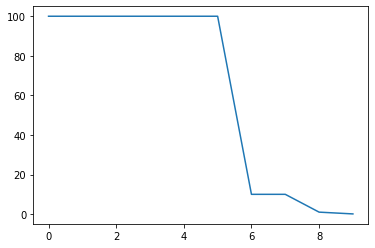
5. ExponentialLR
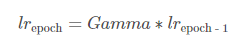
감마를 곱해 Exponetial 하게 lr을 줄인다.
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.1)
lrs = []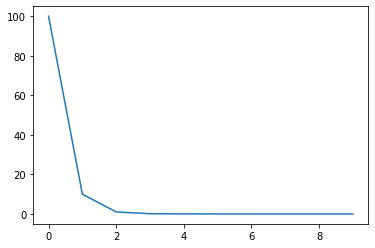
6. CosineAnnealingLR
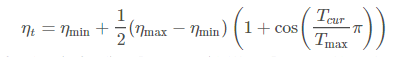
cos함수를 따라서 eta_min까지 떨어졌다가 다시 초기 lr로 돌아온다. 의미는 반복 작업으로 적합 lr을 찾는것
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=100)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=0)
lrs = []
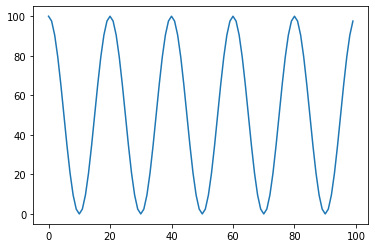
7. ReduceLROnPlateau
성능향상이 없을 때 lr을 감소시키는 것으로 metric 혹은 validation loss 향상 되지 않을 때 epoch이 끝난 후 lr을 줄인다.
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
scheduler = ReduceLROnPlateau(optimizer, 'min')
for epoch in range(100):
train(...)
val_loss = validate(...)
# Note that step should be called after validate()
scheduler.step(val_loss)8. CyclicLR
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.CyclicLR(optimizer, base_lr=0.001, max_lr=0.1,step_size_up=5,mode="triangular")
lrs = []mode = triangular 혹은 triangular2로 ReduceLR과 같이 성능향상(metric,val_loss)가 없을 경우 lr을 줄인다.

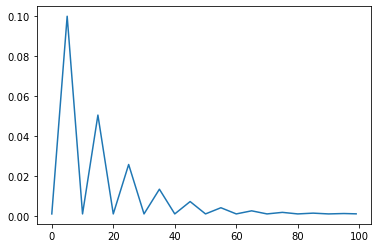

9. OnecycleLR
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.1, steps_per_epoch=10, epochs=10,anneal_strategy='linear')
lrs = []
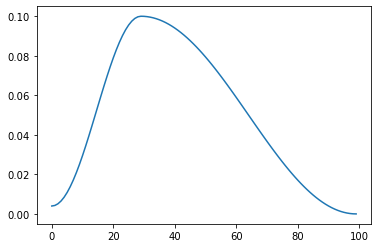
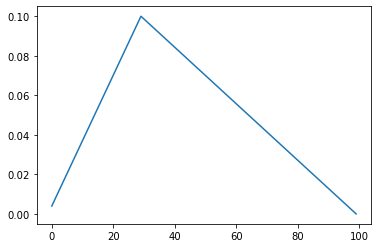
10. CosineAnnealingWarmRestarts

cosine annealing 함수를 따르면서 Ti epoch 마다 다시 시작한다.
model = torch.nn.Linear(2, 1)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
lr_sched = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=10, T_mult=1, eta_min=0.001, last_epoch=-1)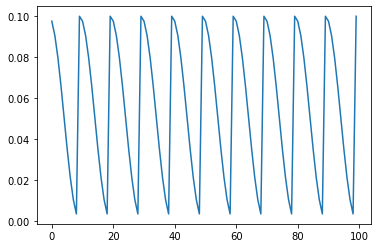
마무리
10가지 방법이 있는데 다 목적은 같고 그 방법도 비슷하다.
참고 :https://www.kaggle.com/code/isbhargav/guide-to-pytorch-learning-rate-scheduling/notebook
:https://sanghyu.tistory.com/113